自制Epub电子书
经常需要自制Epub电子书,群里有朋友也有类似需求,分享一下我的方案。
Why Epub
电子书或文档有很多种格式,例如最常见的PDF,亚马逊Kindle的专有格式azw3(以及之前的azw,mobi),也有人直接用微软的文档格式docx,或者html,或者txt(纯文本)。
很多浏览器(例如静读天下)支持上面所有的格式,所以,电子书格式并不是必须epub。
理论上来说,PDF最通用,表现力最好。以前大量电子书是PDF格式的。但是电子阅读器(手机、Eink、平板)兴起后,PDF需要差不多10寸的屏幕才能比较好的表现,不太适合小屏幕阅读。自亚马逊为其电纸书阅读器推出mobi、azw等格式后,Epub格式也渐渐为大众所知。
不要网友为自己喜欢的阅读材料定制Epub格式的电子书,有的精美程度跟出版物也不相上下。Epub原理上就是一堆html文件的合集,可以通过css文件控制表现形式,文本和格式分离,相较于PDF、docx这种文本和格式混在一起的文档格式,自有其优点。
我是有时候习惯把一堆网文打包整理到电纸书阅读器上使用而考虑自制Epub的。我对格式没有特别精美的要求,能正常展现文字、图片和目录,就可以了。
工具简介
EpubPressX:这个是浏览器插件(Edge、chrome),可以一键把当前打开的多个网页(可以选择)的内容制作成Epub格式电子书。原版epubpress没这个好用,这个很神,速度也很快。如果有多个网文在电脑上看累了,或者想统一保存,用这个直接生成电子书。
Pandoc:一个命令行开源工具,有人做了套壳gui,我习惯命令行。这个很牛逼了,几乎可以从任意一个格式转成另外一种格式,网上有个看起来很震撼的转换图,我就不放了。
Calibre:电子书管理、格式转换工具。kindle只支持azw3,所以我日常用这个将epub转换成azw3。他还附带一个epub编辑器。用我的方法通过docx制作电子书的话,还需要一个epubmerge插件,在Calibre的插件库中直接搜索安装。
白描:一个好用的OCR工具(有网页版和移动版,常用网页版),我少数不多买了付费会员的。(这家也比较良心,不到30,终生会员)
MinerU:pdf(包括doc,png等)转markdown,支持ocr,用大模型转,超牛逼:MinerU-免费全能的文档解析神器。这个最近发现的,用来直接把各种pdf(含扫描pdf)转成html或markdown格式(还支持其他格式)。
文本编辑器:找个顺手的就可以。我习惯用vim。
Docx文件转Epub
- 先把要转成Epub的docx文件放到一个目录下。
- 在这个目录下执行docx2html.bat脚本文件,脚本代码:
1 | @echo off |
- 把生成的全部html文件导入到calibre,然后批量将他们转换成epub文件。
- 用Calibre的EpubMerge插件,将这些epub文件合并成一个新的epub文件,合并的时候可以根据需要调整顺序
- 合并后,用calibre修改调整元数据
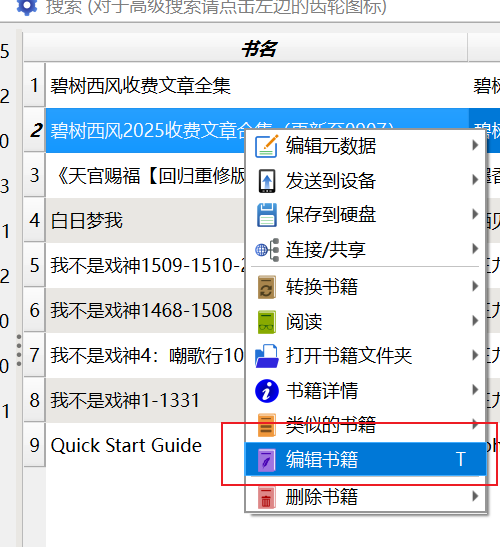
- 如果目录等有问题,可以在calibre中选择编辑书籍,打开编辑工具,编辑工具可以检查/修复epub文件,也可以重新生成目录。

- 电子书主要内容调整好了,就可以在calibre的编辑元数据那里填上一些元数据(书名、作者、日期等),并给电子书找一个好封面。
实际案例(某付费文pdf转epub)
某天制作了一本某某公众号的付费合集,大部分素材是pdf,大概步骤就是把想办法pdf转docx或html,然后用calibre制作epub搞了一整天,累死了,记录一下踩的坑:
- 付费群里很多pdf是截图的,直接全部丢给白描还不行。后来用pdf工具把图片导出来,一篇文章一篇文章的ocr才搞定;(补充:这个估计用MinerU可以直接搞定,用空试一下)
- 有个扫描pdf有意思,导出来一大堆100多张图片,关键的图片不显示,但是直接把pdf丢给白描搞定了
- 某个pdf,用pdf工具把pdf转txt不行,怎么转都乱码,解除复制限制后还不行,只能手动复制
- 好几个文字的pdf不能复制,加锁了,扔给iLovePDF | 为PDF爱好者提供的PDF文件在线处理工具解除了限制
- 扫描ocr出来txt文件有诸多换行的问题。测试了很久,找到了一个解决的方案:查找不是以“。”结尾的行,跟他的下一行合并(用vim):
:g/[^。]$/naormal J可以一直执行,直到没有匹配的。 - txt普通换行通过pandoc转换为html后,不换行,找到一个办法:给每一行增加一个空行:
g/^/normal o - calibre的书籍编辑中,为了生成目录,每个html文件最好有个h1标题。这个目录的名称是从文档中读取的,而不是通过文档名称
- 某次拿到的是pdf,直接copy的话,断行有问题。用ilovepdf转word,ok。但是标粗的字体被转为H1,字体大小不一样。用wps打开,全选标题1样式,然后修改为正文加粗。然后直接用pandoc转换为epub
TXT转Epub
家里娃开始看网文了,本着堵不如疏,和保护眼睛两个原则,我帮他把下载网文转成电子书,供他在电纸书上看。目前大部分网文网站电子书还是txt的比较多,因此需要txt转epub。(后面发现用阅读app,更方便,后话)。TXT转epub,当然可以直接用calibre转,但是不配置的话没有目录(几百万字的网文没有目录一点都不方便),所以要折腾一下:
- 用vim 给txt加##
1 | :%s/^第\d\+章.*/## &/ |
1 | 解释: |
- 把txt文件导入calibre,点击转换,在转换这里配置一下:
填两条正则,让 Calibre 自动识别目录
在 Structure Detection 页面,找到:
Detect chapters at XPath(章节检测 XPath)填:
//h:h2
(因为我们刚才用 ## 把标题变成了<h2>,Calibre 用 h: 前缀代表 HTML 命名空间。)
找到:Insert page breaks before(在检测到章节前插入分页)填同样的:
//h:h2
再切换到 Table of Contents(目录)页面:
Level 1 TOC (XPath)填:
//h:h2
勾选 Auto-generate Table of Contents(自动生成目录)。
找到:TXT Input → Formatting style
下拉框选 “Markdown”(或 “Both”),再转换即可。
这时 Calibre 会先走 Markdown 解析器,把 ## 标题 转成 <h2>标题</h2>,后续 XPath //h:h2 就能正常抓到。
- 然后点转换就可以了
网文txt好多默认首行缩进,不喜欢,用vim给他删除了:
1 | # 删除开头的两个空白字符(tab或空格) |